SEOクローラーとは?仕組み・役割・確認方法をわかりやすく解説

クローラーとは、検索エンジンがWebサイトを巡回して情報を収集・評価するための自動プログラムです。
この記事では、「クローラーの仕組みや役割」「クロールとインデックスの違い」「クロール促進のための内部対策」「Search Consoleでの確認方法」について、専門家がわかりやすく解説します。SEOを始めるにあたって、クローラーの仕組みを正しく理解し、適切に活用することが大切です。
SEOにおけるクローラーとは
SEOの基本を理解する上で、「クローラー」の存在は欠かせません。クローラーは、検索エンジンがWeb上の情報を自動収集し、検索結果に反映するための重要な仕組みです。
ここでは、クローラーの定義や役割を整理し、クロールとインデックスの違い、代表的なクローラーの種類まで解説します。まず、「なぜクローラーの理解がSEOの出発点となるのか」を押さえることが重要です。
クローラーの定義と役割(検索エンジンの巡回ロボット)
クローラーとは、Googleなどの検索エンジンがWeb上のページを自動で巡回するためのプログラムです。主な役割は、インターネット上の膨大な情報を収集し、検索インデックスに登録すること。
これにより、ユーザーが検索した際に関連性の高いページを迅速に表示できるようになります。
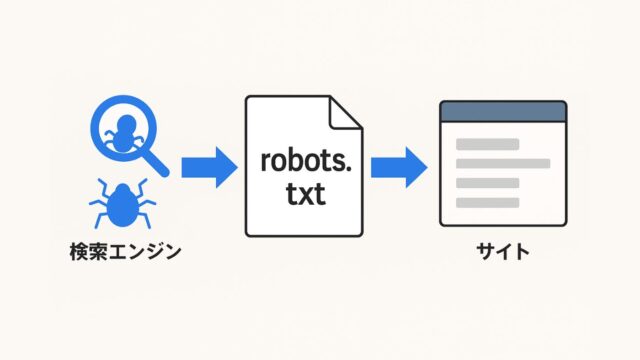
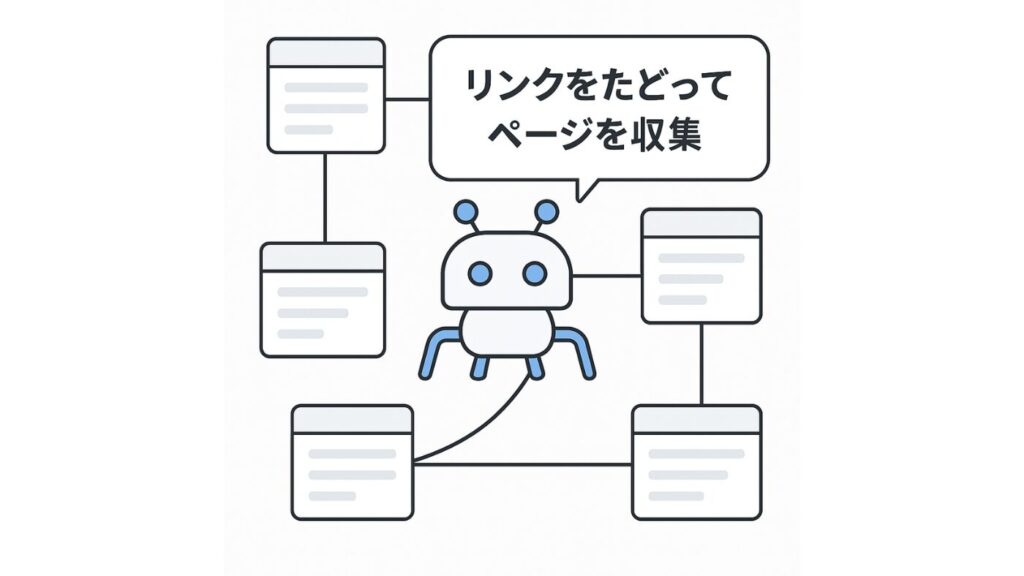
クローラーはリンクをたどって次々にページを探索するため、内部リンクやサイト構造の最適化が重要です。また、robots.txtやnoindexタグによって「どのページをクロールさせるか/させないか」を制御することもできます。クローラーを適切に誘導することが、SEOの成否を大きく左右します。
クロールとインデックスの違い
「クロール」と「インデックス」は、SEOで混同されがちな概念です。クロールはクローラーがページを訪問し、内容を取得する工程。一方、インデックスは取得した情報を検索エンジンのデータベースに登録する工程です。
つまり、クロールされたページが必ずインデックスされるわけではありません。たとえば、重複したコンテンツや品質の低いページ、アクセスできないURLなどは、インデックスされないこともあります。
SEOでは「クロールされること」と「インデックスされること」をそれぞれ別プロセスとして認識し、両方を最適化することが大切です。
クロールとインデックスの違い(概要比較)
| 項目 | クロール | インデックス |
|---|---|---|
| 意味 | ページを訪問し情報を取得 | 取得情報を検索DBに登録 |
| 目的 | 新規・更新ページの発見 | 検索結果に反映するため |
| 管理ツール | robots.txt / サイトマップ | Search Console / URL検査 |
| 対応策 | 内部リンク最適化 | コンテンツ品質向上 |
代表的なクローラー(Googlebotなど)
代表的なクローラーとして最も知られているのが「Googlebot」です。Googlebotには「PC用」や「スマートフォン用」など複数のバージョンがあり、現在はモバイルファーストインデックスにあわせて、主にスマートフォン版が利用されています。
他にも、Bingの「Bingbot」、Yahoo! JAPANの「Yahoo! Slurp」、SNSプラットフォームが使用する、プレビューボット(例:Facebook Crawler)などがあります。
WebサイトのサーバーログやSearch Consoleを確認することで、どのクローラーがどのURLにアクセスしているかを把握可能です。主要なクローラーを把握しておくことは、クロールエラーの解析やrobots.txtの設定に欠かせません。
クローラーとSEOの関係
クローラーはSEOと切っても切れない関係にあります。正しくクロールされなければ、いくら良質なコンテンツであっても検索結果に表示されません。
ここでは、クローラーが検索順位にどのような影響を与えるか、サイト全体のクロール効率を高めるための「クロール予算」という考え方、そしてクローラビリティを高めるための内部施策について解説します。SEO効果を最大化するには、最初にクローラーの視点からサイト設計を見直すことが重要です。
クローラーがSEOに与える影響(順位決定への関与)
クローラーは、SEOの根幹である「検索順位の決定プロセス」に直接関わっています。クローラーが適切にページを巡回し、内容を正確に取得して初めて、Googleはその情報を評価・ランキングに反映できます。
もしクローラーがページにアクセスできなければ、どんなに高品質なコンテンツであっても検索結果に表示されません。逆に、クロール済みでインデックスも完了していれば、アルゴリズムによる評価が行われ、順位に影響します。
つまり、SEOは「上位表示を狙う施策」である前に、「クローラーに正しく認識される環境づくり」から始まります。これがSEOの第一ステップです。
クロール予算(Crawl Budget)の概念
クロール予算とは、Googlebotが1サイトをクロールする際に割り当てる「巡回の上限回数・頻度」のことです。Googleは膨大なWeb全体を効率的に処理する必要があるため、すべてのページを同じ頻度で巡回するわけではありません。
クロール予算は、主に「サーバーの応答速度(負荷)」や「ページの人気・重要度」などによって変化します。たとえば、エラーページや重複したURLが多いと、クロール効率が下がってしまい、重要なページを見落とされるリスクが高まります。
内部リンクを整理し、サイト構造を明確化することで、クロール予算を有効に使い、重要ページを優先的に巡回させることが可能です。
クローラビリティを高める内部施策(内部リンク構造・パンくずリスト・URL最適化)
クローラビリティとは、クローラーがサイト内をスムーズに巡回できる状態を指します。クローラビリティを高めるには、内部リンク構造を整理して重要ページへたどり着きやすくすることが基本です。
パンくずリストを設置することで、クローラーは階層構造を理解しやすくなり、関連性の把握にも役立ちます。また、URLは短く・意味のある構造にすることで、クローラーがページ内容を推測しやすくなります。
さらに、重複URLを正規化する(canonicalタグを設定する)、孤立したページをなくすといった対策も欠かせません。これらの施策を行うことで、クローラーがサイト全体を効率よく把握し、正しく評価できるようになります。
クローラーの仕組みと役割まとめ
クローラーの仕組みを理解することは、SEOで重要となる「見えないプロセス」を知ることにつながります。それは検索エンジンが、クローリング・インデックス・ランキングという3つの段階でページを評価しているからです。
ここでは、その一連の流れとともに、クロール頻度がサイト更新性とどう関係するのか。またクロールエラーが発生した場合の対処法についても具体的に解説します。
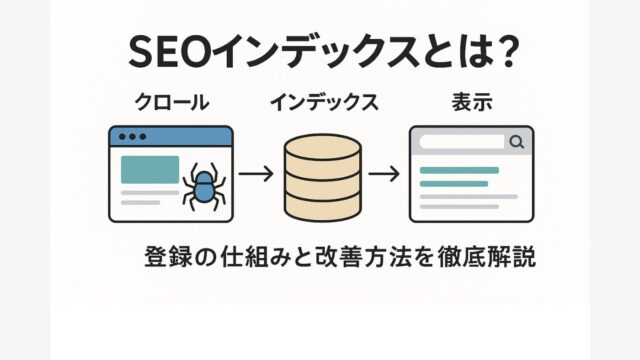
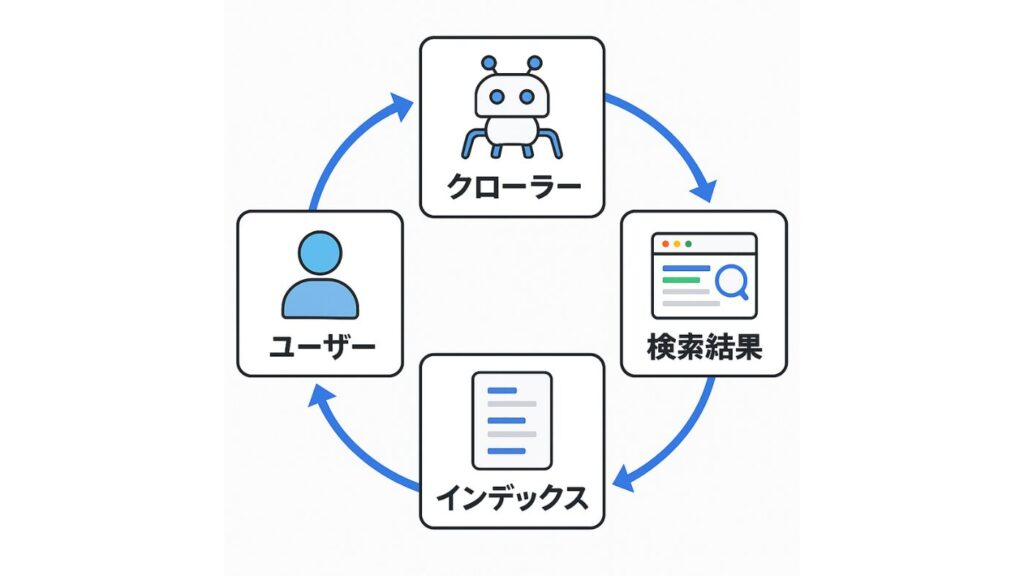
クローリング→インデックス→ランキングの流れ
検索エンジンは、主に「クローリング」「インデックス」「ランキング」の3段階で情報を処理しています。まずクローラーがWeb上を巡回し、新しいページや更新されたページを発見(クローリング)。次に、そのページ内容を解析・保存し、検索データベースに登録(インデックス)します。
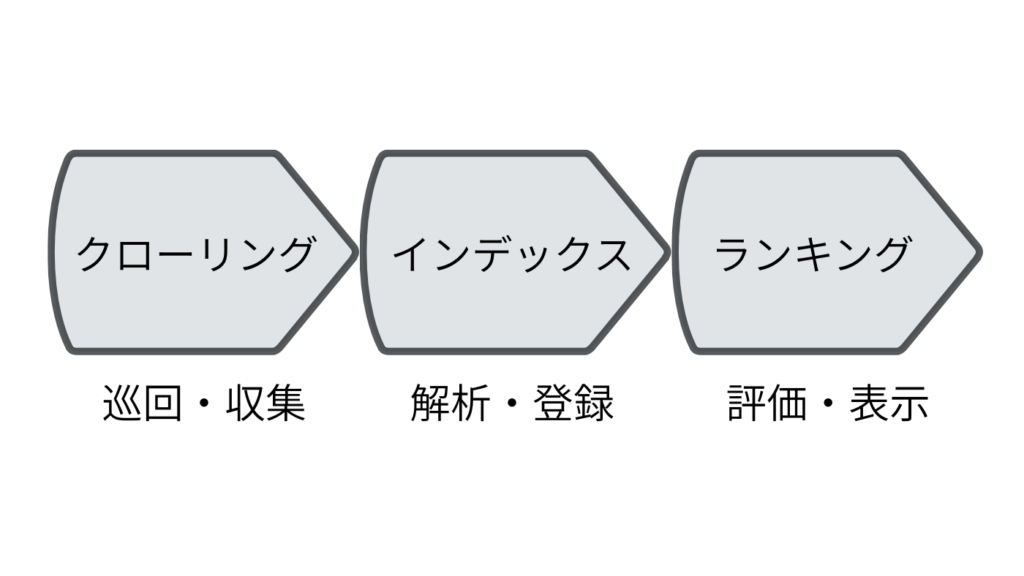
最後に、ユーザーの検索クエリに応じて、インデックスされた情報を評価・並べ替え、検索結果として表示します(これがランキングの工程です)。
つまり、クローリングされなければインデックスされず、インデックスされなければ検索結果にも現れません。SEOは、この3工程をすべて最適化する取り組みといえます。
クロール頻度と更新性の関係
Googleのクローラーは、サイトの更新頻度や重要性に応じてクロールの間隔を調整します。頻繁に更新されるサイトや人気ページは、より短い間隔でクロールされる一方、更新が止まっているサイトはクロール頻度が低くなります。
また、サーバーの応答が遅い、もしくはエラーが多発していると、Googlebotは「負荷が高い」と判断し、クロールを控える傾向があるのです。
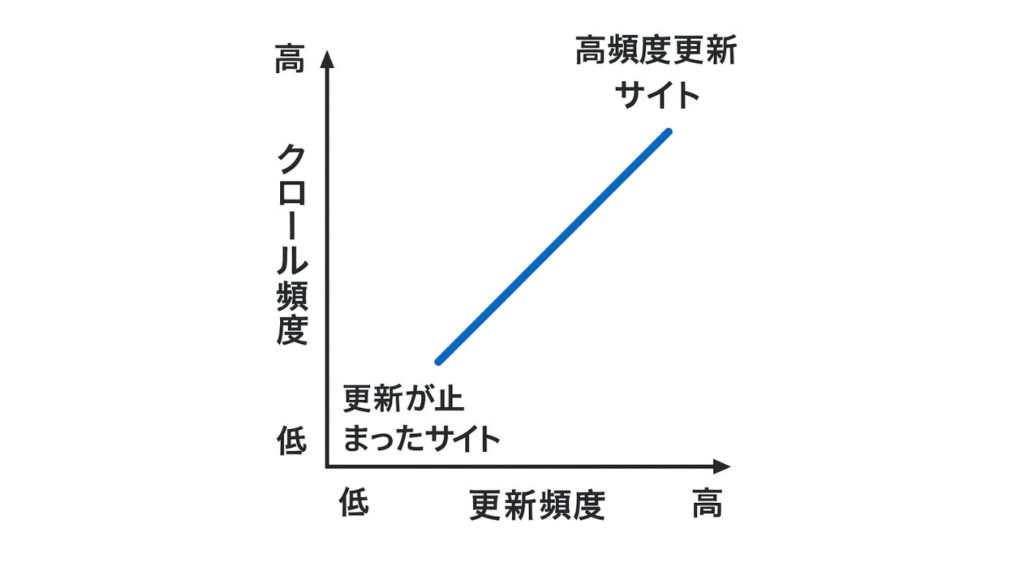
そのため、SEOでは「新しい情報を継続して発信すること(更新性)」と「サイトの表示速度やエラーの少なさ(技術的な安定性)」の両方が重要です。これらを両立することで、クロール頻度が保たれ、検索エンジンからの評価も安定していきます。
クロールエラーの種類と改善方法
クローラーがページを巡回する際、アクセスできなかったり、データを取得できなかったりする場合には「クロールエラー」が発生します。代表的なエラーとして、404(ページが存在しない)、500(サーバーエラー)、リダイレクトループなどがあります。
これらを放置すると、クローラーが有効なページにたどり着けず、インデックスの精度が下がる原因になるのです。
改善には、Search Consoleで「クロールエラー」を定期的に確認し、不要URLの削除・リダイレクト設定・内部リンク修正を行うことが重要です。
クローラーが迷わず正しい情報を取得できるように整えることが、SEOの技術的土台になります。
クローラーにクローリングさせる方法
「ページを作ったのに検索に出てこない」——その原因の多くは、クローラーがまだページを認識していないことにあります。
ここでは、Google Search Consoleを活用してクロールを促進する方法、XMLサイトマップの送信によるページ発見の支援、robots.txtによるクロール制御の最適化について解説します。クローラーを積極的に誘導し、サイト全体の評価を向上させることが重要です。
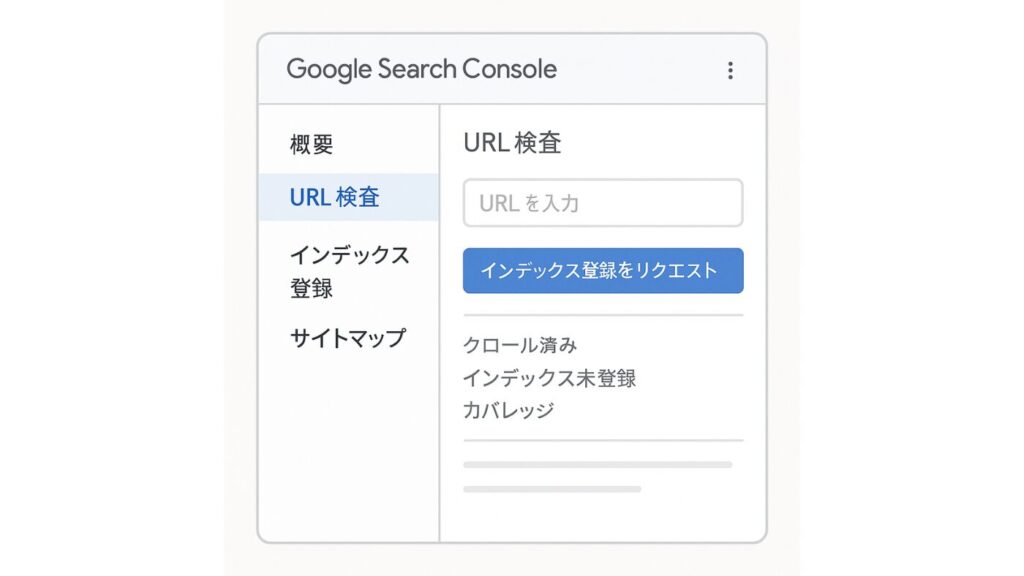
Google Search Consoleの「URL検査ツール」活用
Google Search Consoleは、クローラーとの「橋渡し」となる公式ツールです。その中でも「URL検査ツール」は、特定のページをGoogleに直接クロール依頼できる機能として非常に有効です。
公開したばかりの新記事や更新後の重要ページは、URL検査ツールで「インデックス登録をリクエスト」することで、クローラーが優先的に巡回してくれる可能性が高まります。
また、このツールではクロール済みか否か、インデックス状況、発生している技術エラー(モバイル対応・構造化データなど)も確認可能。SEO担当者は、更新作業のたびにURL検査ツールでクロール促進と状態チェックを習慣化するといいでしょう。
XMLサイトマップの送信
XMLサイトマップは、サイト内のページ構成やURL情報を検索エンジンに正確に伝えるための「設計図」のようなファイルです。クローラーはこれを読み込むことで、効率的にページを発見し、漏れのないクロールを実現します。
とくに、階層が深いページや内部リンクが少ないページは、XMLサイトマップで明示することがクロールのきっかけになります。
Search Consoleの「サイトマップ」メニューから送信することで、Googlebotは定期的に内容をチェックし、更新状況に応じて再びクロールし始めるのです。
SEOにおいては、動的生成(CMSプラグインなど)で常に最新のサイトマップを維持することが推奨されます。
robots.txtの設定と確認
robots.txtは、クローラーに対して「どのページをクロールしてよいか/禁止するか」を指示する設定ファイルです。誤った記述をすると、重要ページがクロール対象外になることもあるため注意が必要です。
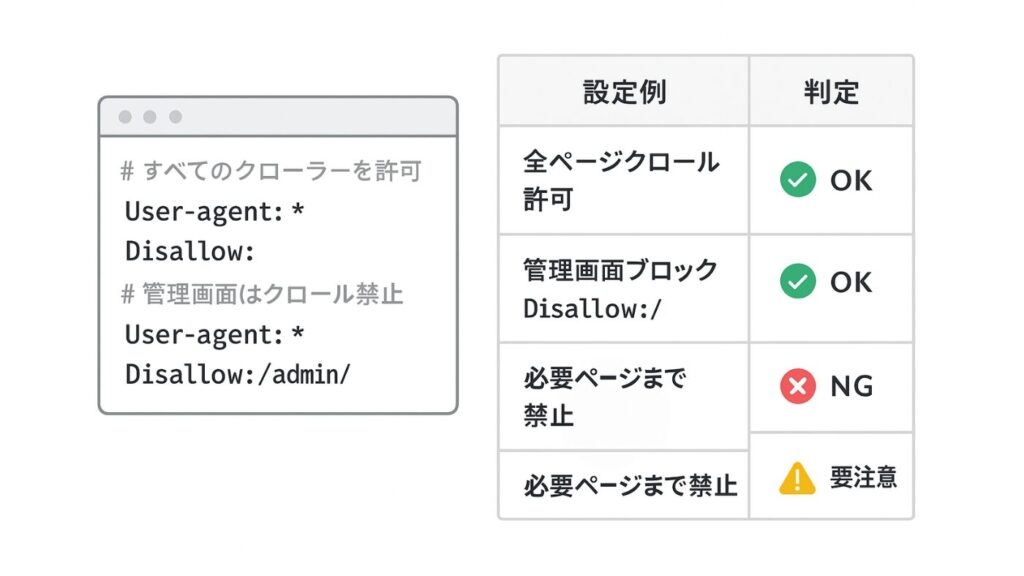
一般的には、管理画面やシステムページなどインデックスが不要な領域のみ「Disallow」を指定し、公開ページはすべてクロールを許可しておくことが原則とされます。
設定後は、Search Consoleの「robots.txtテスター」でエラーの有無を確認しましょう。また、robots.txtはクロール制御のみであり、インデックス制御は「noindex」メタタグで行うのが正しい運用です。
適切なrobots.txtの管理は、クローラーの正しい誘導とサイト全体の評価の安定につながります。
クローラーにインデックスされたことを確認する方法
ページを公開したら、それが実際に検索エンジンに登録(インデックス)されているかを確認する必要があります。ここでは、簡易的に状況を把握できる「site:検索」と、正確な分析が可能なGoogle Search Consoleの確認方法を紹介。あわせて、インデックスされない場合に見直すべき原因と改善策についても整理します。
「site:」検索による確認
最も手軽にインデックス状況を確認する方法が、「site:」検索です。Googleの検索窓に「site:ドメイン名(例:site:example.com)」と入力すると、そのドメイン内でインデックスされているページの一覧が表示されます。
特定のURLを確認したい場合は、完全なURLを指定すれば、そのページがインデックス済みかどうかを判別可能です。
ただし、「site:」検索は手軽な方法ですが、結果がリアルタイムで反映されるわけではなく、すべてのページが表示されない場合もあります。そのため、完全なインデックス状況を知るには注意が必要です。
大まかな傾向をつかむには有効ですが、詳細なクロール状況やインデックス状況を把握するには、Search Consoleの利用が不可欠です。
Google Search Consoleでのインデックス確認
Google Search Consoleでは、URL単位で正確なインデックス状況を確認できます。とくに「URL検査ツール」では、そのページがクロール済みか、インデックス登録されているか、エラーが発生していないかを詳しく確認可能です。
また、「インデックス登録」メニューの「ページ」レポートを使うと、サイト全体のインデックス状況をまとめて確認できます。そこから「インデックス済み(有効)」「除外(noindexやリダイレクトなど)」「エラー(アクセスできない、送信拒否など)」といった内訳も一覧で見ることができます。
このレポートを定期的に確認することで、サイト全体の健全性を維持し、クローラーが正しく情報を取得しているかを把握できるのです。
インデックスされない場合の原因と対処
クロールはされているのに、インデックスされない場合はいくつかの原因が考えられます。代表的な要因は、(1)コンテンツの品質不足(2)重複ページの存在(3)noindex指定(4)クロールエラー(5)内部リンクからの孤立です。
まず、Search ConsoleのURL検査で「クロール済み – インデックス未登録」と表示される場合、コンテンツのオリジナリティや情報量を見直しましょう。
重複したページや低品質なページは統合または削除し、内部リンクやサイトマップでクロール経路を確保しましょう。
また、robots.txtやメタタグのnoindex設定が誤っていないか確認することも重要です。
継続的な改善により、クローラーは「価値あるページ」と判断し、インデックス登録が促進されます。
内部リンクについてはこちらで詳しく解説しています。

クローラーを理解することはSEOの第一歩
SEOは、クローラーを正しく理解することから始まります。クローラーは、検索エンジンがWebサイトを評価するための入り口であり、SEO戦略全体の基盤です。
ここでは、「なぜクローラー理解が戦略に不可欠なのか」「初心者が陥りやすい誤解」そして「正しい理解がもたらす長期的な成果」について、実践的な視点でまとめます。
クローラー理解がSEO戦略に不可欠な理由
クローラーの理解は、SEO戦略を立てる上での「出発点」です。どれほど質の高いコンテンツを用意しても、クローラーがページを認識しなければ評価はされません。
つまり、検索エンジンとの最初の接点を設計することが、SEOの本質といえます。
クローラーの動きを理解すれば、どのページを重点的にクロールさせるべきか、どのように内部リンクを構築すべきかといった判断が可能になります。
また、技術的SEO(構造化データ、モバイル対応、ページ速度など)の施策も、すべてはクローラーが正確に情報を取得できる環境整備が前提です。
「どう評価されるか」を考える前に、「どう見つけてもらうか」を理解することが、戦略的SEOの第一歩です。
初心者が陥りがちな誤解(クロール=インデックスではない)
SEO初心者がよく誤解するのが、「クロールされた=検索結果に表示される」という認識です。実際には、クロールとインデックスは別の工程であり、クロールされたからといって自動的にインデックスされるわけではありません。
検索エンジンはクロール後、ページの内容・品質・独自性・ユーザー有用性を評価し、一定の基準を満たす場合にのみインデックスへ登録します。
この違いを理解せずに、クロール促進だけに注力しても成果は出ません。
SEOでは、クロール→インデックス→評価→表示 の各プロセスを分けて捉え、それぞれに適した施策を講じることが大切です。
正しい理解がもたらす成果(サイト全体の評価向上)
クローラーの仕組みを正しく理解し、サイト構造や内部施策を最適化できるようになると、検索エンジンはより多くのページを正確に認識し、評価も安定していきます。
結果として、個々のページだけでなく、サイト全体の信頼性や専門性が高まり、検索順位の向上にもつながります。
とくに、クロールエラー改善・内部リンク整備・サイトマップ更新などは、短期的な順位変動に左右されない長期的な資産形成の施策です。
クローラーを適切に活用することは、単なるテクニカルSEOではなく、サイト運営全体の品質向上に直結する取り組みです。
よくある質問(FAQ)

Q1. ページがクロールされないのはなぜ?
A.クローラーが巡回できない原因には、内部リンクの不足・XMLサイトマップ未送信・robots.txtの誤設定などがあります。まずは、Search Consoleでインデックス状況を確認し、クロールエラーや除外ステータスを点検しましょう。
Q2. 新しく公開した記事を早くクロールさせるには?
A.Google Search Consoleの「URL検査ツール」でインデックス登録をリクエストすると、クローラーが優先的に巡回する可能性が高まります。あわせて内部リンクを張り、関連性を明確にしておくとクロール効率が向上します。
Q3. クロール頻度を上げるためにできることは?
A.定期的な更新と高品質なコンテンツ提供が最も効果的です。サイトの応答速度を改善し、404・500エラーを解消することで、Googlebotが負荷を感じず頻繁に巡回しやすくなります。
H2:SEOにおけるクローラーのまとめ
クローラーは、検索エンジンとWebサイトをつなぐ架け橋です。どれだけ良質な記事を書いても、クローラーが正しく巡回しなければ、インデックスにも登録されず、検索結果に反映されません。
SEOでは、まず「内部リンク構造の最適化」「XMLサイトマップの送信」「robots.txtの整備」によって、クロール予算を有効に活用できる環境を整えることが重要です。
さらに、Google Search Consoleでクロール状況やエラーを定期的に確認し、改善を積み重ねることで、インデックス精度と評価が向上します。
クローラーの仕組みを理解し、適切にクローラーを誘導できるようになれば、SEOの成果を着実に高めることができます。