SEO robots.txtとは?正しい設定とSEO効果を解説
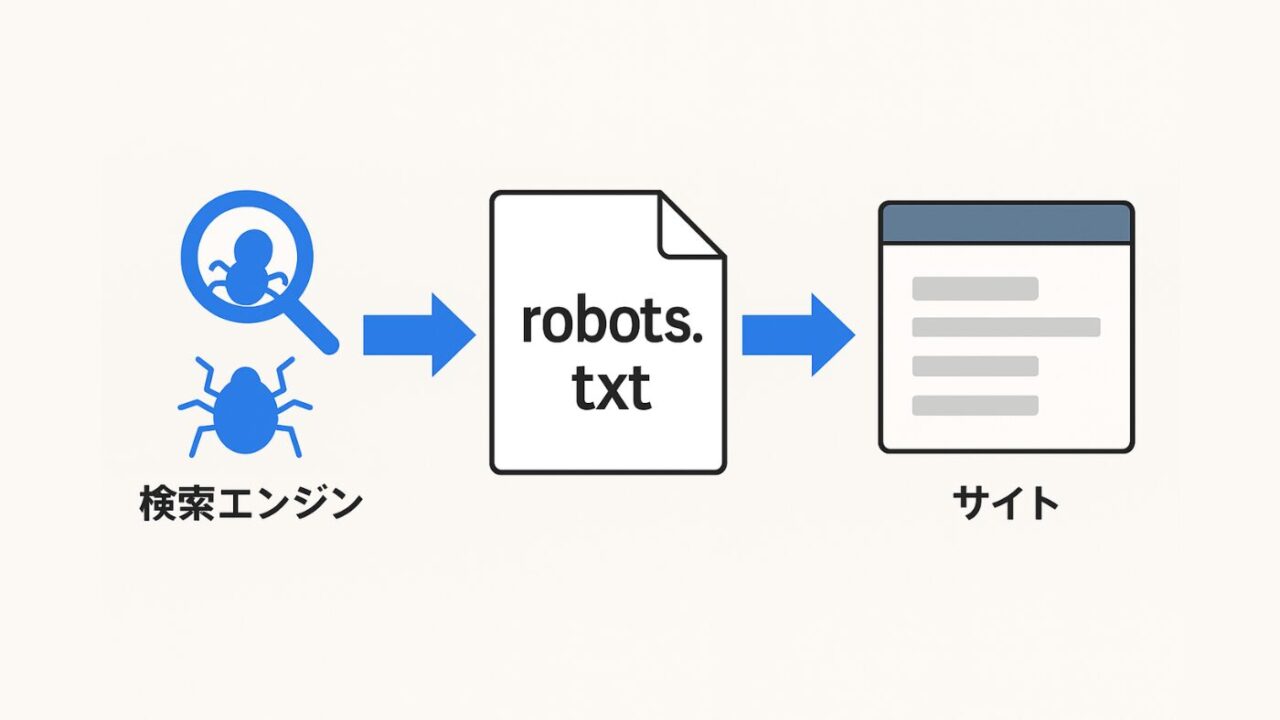
robots.txtは、検索エンジンのクローラーに対して「どのページをクロールしてよいか」を指示する重要なファイルです。
この記事では、SEOの観点からrobots.txtの正しい設定方法やSEO効果を高めるための基本構文、書き方、注意点について解説します。また、robots.txtの役割や設定方法を整理し、全体像を体系的にまとめてご紹介します。
robots.txtとは?SEOにおける役割と重要性
robots.txtは、Webサイト運営者が検索エンジンのクローラーを制御するために使用する最も基本的なファイルです。
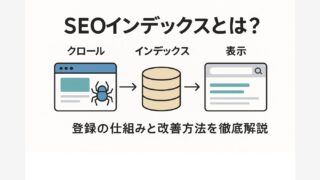
SEOの観点では、不要なページをクロールさせず、重要なページへクローラーのリソースを集中させることが目的です。検索エンジンの仕組みでは「クロール」と「インデックス」が別工程であり、この工程を理解していないと、誤った設定をしてしまう恐れがあります。
robots.txtは、noindexやmetaタグよりも先にクローラーの挙動を制御するため、SEO戦略の基盤として非常に重要な役割を果たします。
クロールとインデックスについては以下の記事が参考になります。

robots.txtの基本的な役割
robots.txtは、検索エンジンのクローラーがアクセスしてよい範囲を指定するための制御ファイルです。サイト運営者はこのファイルを使って「クロールさせたくないページ」や「アクセス制限を設けたい領域」を指定できます。
これにより、不要なページへのリソース消費を抑え、検索エンジンの評価対象を最適化することが可能になります。
robots.txtとnoindexの違い
robots.txtは「クロールを禁止する指令」、noindexは「インデックス登録を禁止する指令」です。robots.txtでブロックされたページはクロール自体が行われず、noindexタグはページをクロール後に検索結果から除外します。
誤ってrobots.txtで重要ページを遮断すると、Googleはその内容を認識できず、インデックスできません。
robots.txtはディレクトリやURLパス単位でクローラーのアクセスを制御するのに対し、noindexはページ単位で「検索結果に表示させない」ことを指示します。そのため、robots.txtはサイト全体の巡回設計、noindexは個別ページの公開制御に使い分けるのが基本です。
両者を併用する際は、robots.txtでページへのアクセス自体をブロックすると、検索エンジンがそのページにたどり着けず、noindexタグの指示も認識できない点に注意が必要です。
ページ単位でインデックスさせたくない場合は、HTMLに <meta name=”robots” content=”noindex”> を記述します。一方、テスト環境などサイト全体を検索エンジンにインデックスさせたくない場合は、robots.txt に Disallow: / を記述します。
ただし、robots.txtだけでは検索エンジンによるインデックス登録を完全に防ぐことはできません。すでにインデックスされたURLを必ず検索結果から除外したい場合は、noindexを併用する必要があります。
robots.txtがSEO評価に与える影響
robots.txt自体には直接SEO評価を上げる効果はありませんが、クロールの最適化によって間接的にSEO効果が期待できます。
たとえば、重複ページや管理画面などを除外することで、クロールバジェットを有効活用し、主要ページのインデックス速度を向上させることができます。結果として検索結果の安定化や評価の早期反映につながります。
robots.txtの基本構文と書き方
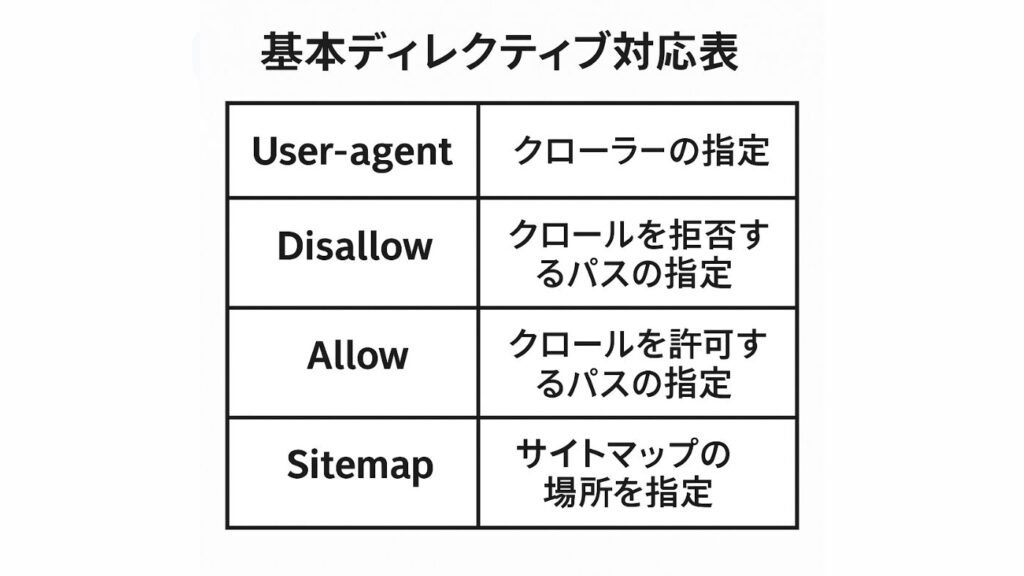
robots.txtは単純なテキストファイルですが、構文を誤ると意図しないクロール制御が発生するため、記述ルールの理解が不可欠です。
基本構文は「User-agent」「Disallow」「Allow」「Sitemap」の4つの要素からなり、検索エンジンに対してクロールの許可・禁止や、サイトマップの参照範囲を明確に示します。
とくにDisallowとAllowの優先順位を誤ると、特定ページが意図せずクロール対象外になることがあります。AllowはGoogleなど主要クローラーのみ対応しており、すべての検索エンジンが解釈するわけではありません。
適切なコメントを併記することで運用担当者間の引き継ぎも容易になり、長期的に安定したSEO運用が可能です。
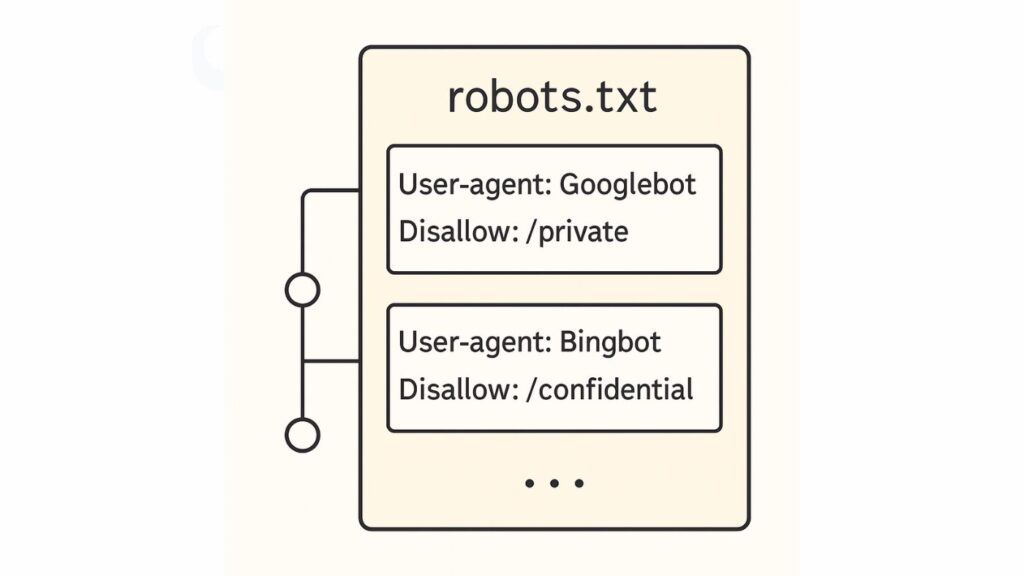
例:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
robots.txtでクロールを制御するポイント
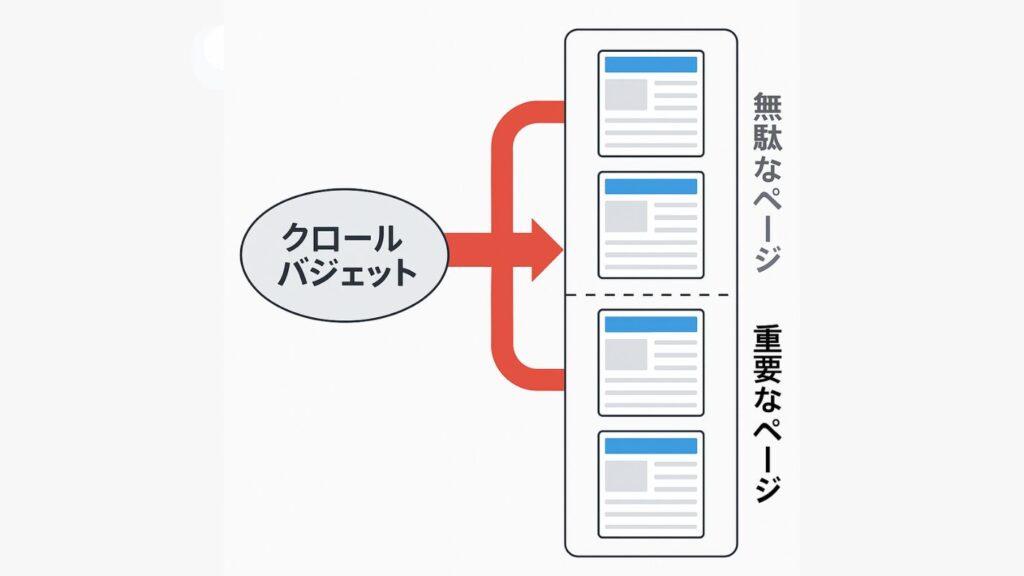
robots.txtの主な目的は、サイト全体のクロール効率を高めることにあります。検索エンジンのクローラーは無制限に巡回できるわけではなく、サイトごとに割り当てられたクロールバジェットを消費して動作します。
そのため、インデックス不要なページを的確にブロックし、重要ページにリソースを集中させることがSEO最適化の鍵です。
なお、robots.txtではクロール頻度を直接制御することはできません。たとえば、GoogleはCrawl-delayディレクティブに対応していないため、クロール頻度を変えたい場合はサーバー設定など他の方法を使う必要があります。
クロール拒否すべきページの判断基準
クロールを拒否すべき対象は、検索結果に表示する必要のないページです。たとえば管理画面、テスト環境、内部検索結果ページ、パラメータ付きURLなどが該当します。これらを除外することで重複コンテンツや低品質ページの評価を回避できます。
ユーザーがアクセスすべき情報を優先的にクロールさせることがSEO最適化の基本です。
クロールバジェット最適化の考え方
Googleのクローラーはサイトごとにクロール頻度の上限(クロールバジェット)を持っています。robots.txtで不要ページを制御することで、このバジェットを有効に使えます。
とくに大規模サイトでは「更新頻度が高いページ」「コンバージョンに直結するページ」を優先的にクロールさせる設計が重要です。
robots.txt作成時の注意点とよくある誤設定
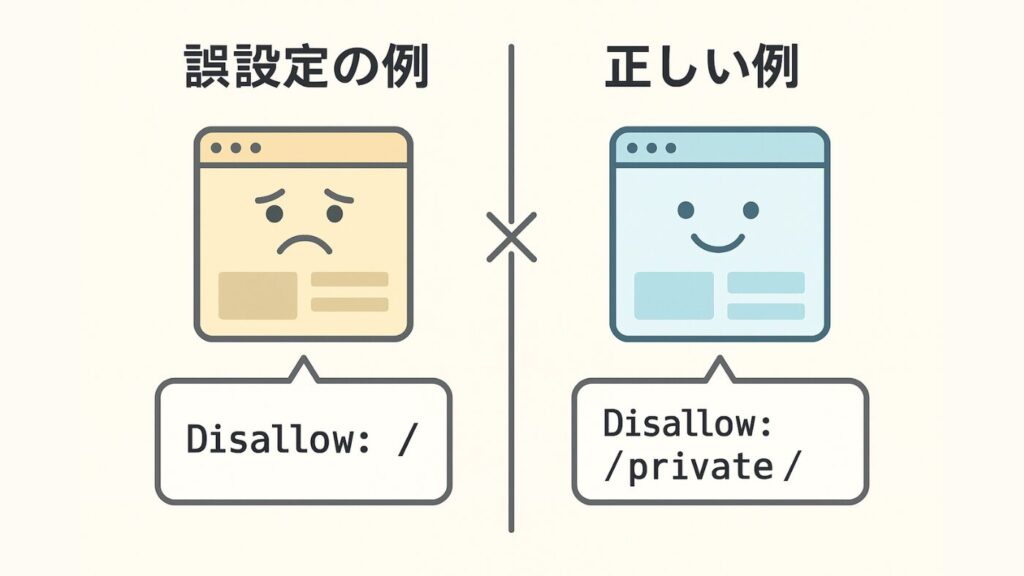
robots.txtは強力な制御手段である反面、一つの誤設定でサイト全体のインデックスが停止するリスクを伴います。とくに Disallow: / のような記述は全ページを対象外にしてしまうため、管理ディレクトリなどを限定的に指定する方がいいでしょう。
また、noindexやcanonicalとの使い分けを間違えると、クロール制御とインデックス制御が互いに干渉して意図しない結果になることがあります。
テストやプレビュー用の設定を本番環境に適用する際は、必ずGoogle Search Consoleのテスター機能で事前に確認し、安全性を確かめましょう。
誤って重要ページをブロックする例
誤設定で多いのは、トップページや主要ディレクトリをDisallowで丸ごとブロックしてしまうケースです。
たとえば Disallow: / と記述すると、サイト全体がクロール不可になります。特定の管理ディレクトリのみを除外したい場合は、正確なパス指定が不可欠です。設定後は必ずGSCでテストを行いましょう。
よくある誤設定の例
- Disallow: / を誤って記述し、全ページをブロックしてしまう
- Sitemap URL の書き間違い(httpsとhttpの混在など)
- AllowとDisallowの順序を誤り、意図しない適用順序になってしまう
- 開発環境の設定をそのまま本番環境に反映してしまう
- コメント行の記号ミス(例:#の記載漏れ など)
noindexやcanonicalとの混同に注意
robots.txtでアクセスを禁止したページにnoindexやcanonicalを設定しても、検索エンジンのクローラーはそのページにアクセスできないため、これらの指示は認識されません。
これらの指令は「クロールされた後」に有効になるため、重複コンテンツを制御する際はnoindexを優先し、robots.txtは補助的に使うのが正解です。
robots.txtの設置場所と確認方法
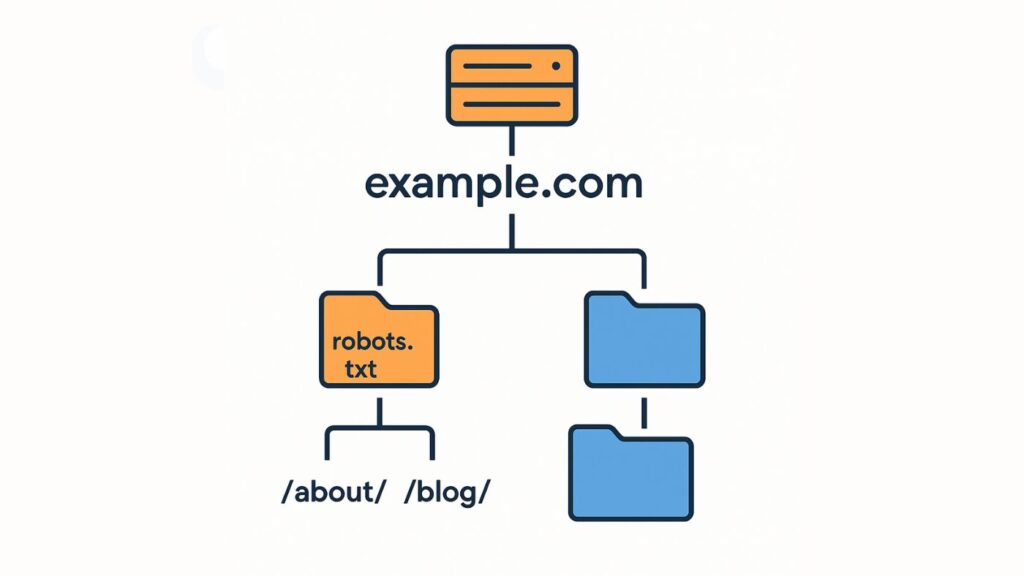
robots.txtファイルは、検索エンジンが最初にアクセスする入り口です。そのため、設置場所が正しくなければ機能しません。ファイルは必ずドメイン直下(https://example.com/robots.txt)に設置します。
また、サブドメインごとに独立したrobots.txtを設置することは可能です。サブドメインとは、メインドメインの前に任意の文字列を付けて作る独立した領域(例:blog.example.com や shop.example.com)で、別サイトとして扱われます。各サブドメインには専用のrobots.txtを設置することが可能です。
設置後はブラウザで直接アクセスして内容を確認し、Google Search Consoleの「robots.txtテスター」で挙動をチェックします。エラーやキャッシュ反映遅延がある場合は、定期的に更新し、最新設定を確実に反映させましょう。
サーバー上での設置手順
robots.txtは必ずドメイン直下(例:https://example.com/robots.txt)に配置します。サブディレクトリに配置するとrobots.txtは無効となり、動作しません。
robots.txtは、FTPやCMSのファイルマネージャを利用し、UTF-8で保存します。設置後はブラウザでURLを直接開き、内容が正しく表示されるかを確認しましょう。
GSCでの検証とエラー対処法
Google Search Consoleの「robots.txtテスター」機能を使うと、クローラーのアクセス結果を即時に確認できます。エラーがある場合は、DisallowやAllowの書式を見直します。
また、変更内容はキャッシュの影響で反映に数日かかることがあるため、重大な修正はURL検査ツールでインデックス登録をリクエストして反映を促すとよいでしょう。
WordPressでのrobots.txt設定方法
WordPressでは、インストール直後から仮想robots.txtが自動生成され、一般的なクローラー制御が行われています。
多くの場合 /wp-admin/ がDisallow指定され、一般のページはクローラーに許可。しかし、SEO効果をさらに高めたい場合は、独自のrobots.txtファイルを作成し、プラグインやテーマに合わせて細かく制御することが推奨されます。
Yoast SEOやRankMathなどのプラグインを利用すると、GUI上でrobots.txtの生成や編集が容易に行えます。また、複数サイトを運営している場合でも一貫した設定管理が可能です。なお、実ファイルを設置すると、WordPressの仮想robots.txtよりも実ファイルが優先されます。
WordPress標準のrobots.txt設定
WordPressはデフォルトで仮想robots.txtを自動生成します。一般的には /wp-admin/ をDisallowし、それ以外のページはクローラーに許可しており、安全な設定です。
ただし、プラグインやテーマの構成によっては独自にrobots.txtを設置した方がよい場合もあります。SEO強化を狙う場合は実ファイル化して細かく制御するのが望ましい場合もあります。
Yoast SEOやRankMathでの生成方法
Yoast SEOやRank Mathでは、管理画面からrobots.txtの編集および生成が可能です。これらのツールはDisallowやSitemapの追加をGUIで行えるため、初心者でも誤設定を防ぎやすくなっています。複数サイトを運営する際には、テンプレート設定を活用することで一貫性を保てます。
SEOを高めるrobots.txt最適化の考え方
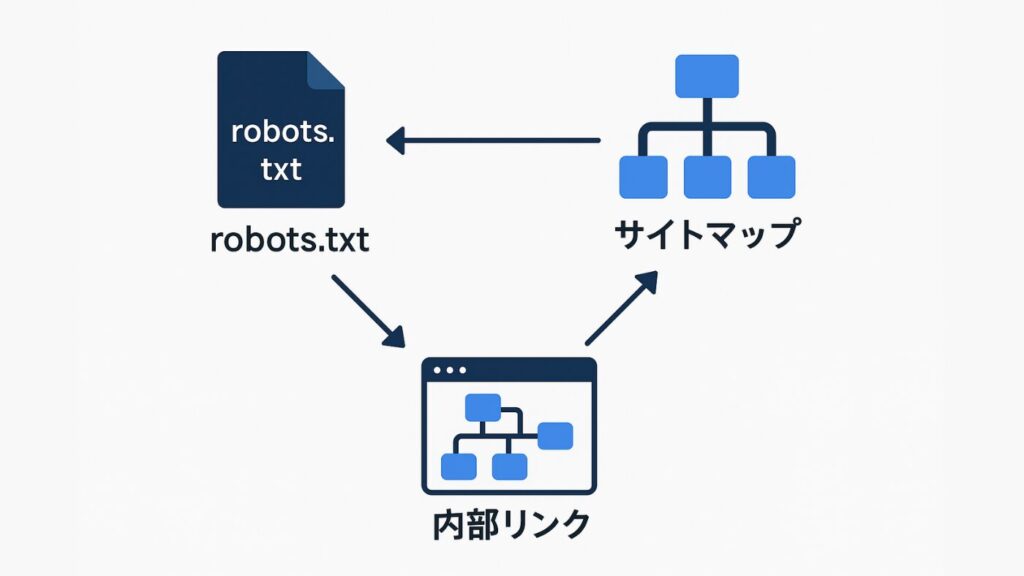
robots.txtは単なる制御ファイルにとどまらず、SEOを支える戦略的要素です。クロール制御を通して、検索エンジンが重要ページを効率的に把握できるように設計することが求められます。
また、内部リンク構造・サイトマップ・構造化データとの整合性を保つことで、Googleにとって理解しやすいサイト構造を実現できます。さらに、GPTBotやAhrefsBotなどの第三者クローラー対応を定期的に見直すことで、技術的SEOの精度を高めることが可能です。
クロール制御と内部リンク最適化の関係
robots.txtの制御は、内部リンク構造の最適化と密接に関係します。クロールが許可されたページ同士を内部リンクでつなぐことで、検索エンジンがサイト全体を効率的に理解します。
逆に孤立ページが多いとクロール効率が下がるため、サイトマップやパンくずリストとの連係が不可欠です。

構造化データ・サイトマップとの整合性
robots.txtで制御する範囲と、サイトマップで公開するURL群が矛盾すると、Googleは混乱します。たとえばSitemapに掲載されたURLがDisallowでブロックされていると、インデックスされません。
構造化データを活かすには、robots.txt・Sitemap・schema markupを一貫した方針で設計する必要があります。
SEO専門家が推奨するrobots.txt設定例
最適なrobots.txtは「安全+効率」のバランスを取ることが重要です。たとえば、以下のような設定は一般的な最適構成です。
例
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
このように、robots.txtの各要素がどのような意味や役割を持つかを理解しておくことが重要です。
まず、User-agent はどの検索エンジンに対して指令を出すかを指定します。ここでは「*」を指定することで、すべてのクローラーを対象としています。
次に、Disallow はクロール禁止したいパスを指定。たとえば /wp-admin/ と記入すると、WordPressの管理画面へのクローラーのアクセスを防げます。これにより管理領域をクロール対象から除外でき、セキュリティの確保やクロールバジェットの節約が可能です。
そのうえで、Allow は例外的にクロールを許可する領域を指定し、/wp-admin/admin-ajax.php を許可することで、AJAX通信(ページを再読み込みせずにサーバーとデータをやり取りする非同期通信)が正常に動作します。
最後に、Sitemap はサイト全体の構造を検索エンジンに伝える役割です。
これらを組み合わせて設定することで、クロール効率とサイトの安全性を両立させることできます。また、GPTBotやAhrefsBotなど新しいクローラーにも注意し、定期的に設定を見直すことが大切です
まとめ|robots.txtを正しく設定しSEOを最大化する
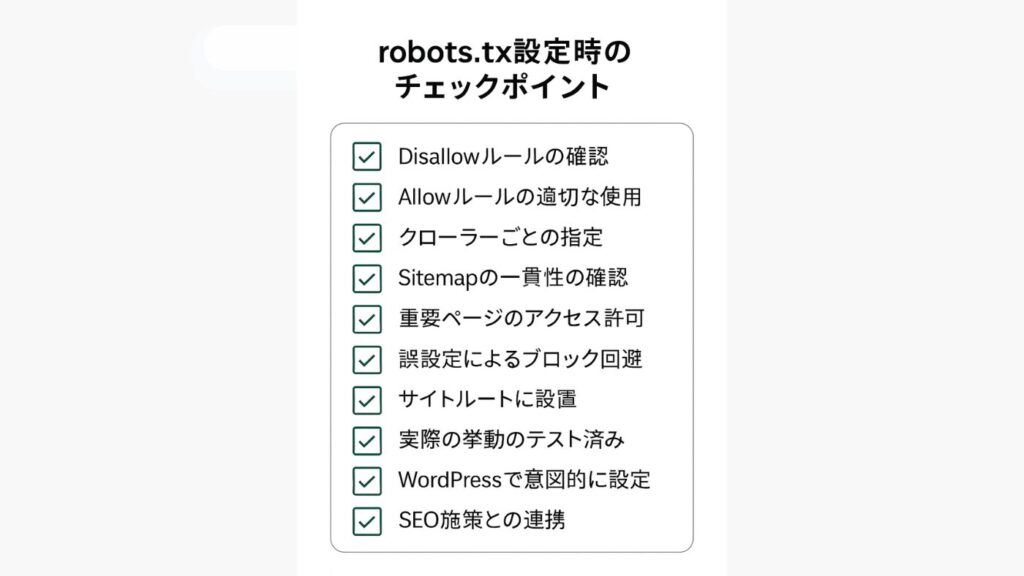
robots.txtは、Webサイトの健全なクロールとインデックスを維持する上で不可欠な要素です。設定を誤るとSEOに悪影響を与える可能性がありますが、基本構文と注意点を理解すれば安全に運用することが可能です。
この記事で紹介したチェックリストや最適化のポイントを実践することで、クロール効率が向上し、主要なページの評価を早く受けられるようになります。定期的にrobots.txtを見直し、検証することで、サイト全体のSEOパフォーマンスが安定して向上します。
設定時のチェックリスト
- サイト直下に配置されているか
- 主要クローラー(Googlebotなど)に対応しているか
- Sitemapを正しく指定しているか
- noindexやcanonicalと矛盾していないか
- GSCでテスト済みか
これらを確認することで、誤設定によるインデックス漏れを防止できます。
SEO効果を維持するための更新ポイント
サイト構成を変更した際や新ディレクトリを追加した際は、robots.txtの更新を忘れずに行いましょう。古い制御ルールを放置すると、クロール効率が下がり、SEO評価の反映が遅れる原因となります。
半年に一度はrobots.txtを点検し、Googlebotの仕様変更にも追随することで、安定した検索評価を維持できます。